Article type
Year
Abstract
Background:
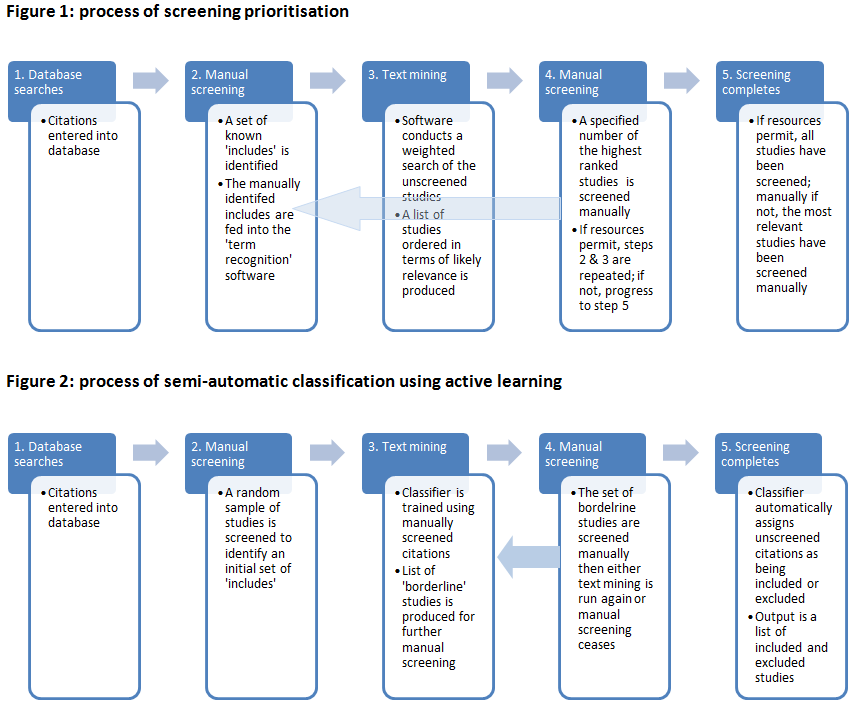
The task of identifying relevant studies for systematic reviews in an unbiased way is increasingly time consuming. Text mining may be able to assist in the screening process in two ways: (1) by prioritising the list of items for manual screening so that the studies at the top of the list are those that aremost likely to be relevant (‘screening prioritisation’; Fig. 1); (2) by using manually-assigned include/exclude decisions in order to ‘learn’ to apply such categorisations automatically (‘semi-automatic classification’; Fig. 2).Objectives:
To evaluate the performance of two text mining methods to reduce screening workload by assessing their performance in completed reviews.Methods:
Data from ten previous reviews covering health care and public health were entered into the system. Data included the record’s title and abstract text plus reviewer decisions on whether to exclude the study or not. We ran simulations of the screening process (ten times for each condition) testing how the following affected the performance of the two text mining processes: the size of the initial training sample (5, 10, 20 or 40 studies); the method and frequency of re-running the search/training the classifier (after 5 or 20 includes were identified, or after 25, 250 or 500 records were screened). Performance was assessed using accuracy, precision, recall/sensitivity, F-measures, and Area Under a (ROC) Curve and burden.Results:
There was some variability between the performance of the tools between reviews, but consistency within reviews. Screening workload can be reduced, but at the risk of missing potentially relevant studies.Conclusions:
A balance needs to be drawn between the number of studies it is feasible to screen manually and the gain that accrues from screening thousands of ultimately irrelevant studies. Text mining is likely to have a role to play, though further evaluation is required.Images
{kind=link}